Detectify Content Moderation API
A powerful, real-time content moderation API that scans multilingual text for 11 key policy-sensitive categories. Effortlessly flag spam, NSFW, hate speech, harassment, violence, self-harm, CSAM, extremism, misinformation, PII, and obfuscation—all via a single endpoint.
Enjoy all the awesome features of Detectify that make it the best choice for your needs:
Accepts and analyzes text in multiple languages for global platform safety.
Flags and scores 11 critical content categories in real time.
Provides concise explanations for each flagged category.
Delivers an aggregate risk score and highlights the top-scoring category.
Simple HTTP interface—no SDK required, works in any language or framework.
Detectify Content Moderation API
Welcome to the Detectify Content Moderation API—a powerful, real-time service that scans multilingual text for 11 policy-sensitive categories. Built for simplicity and speed, Detectify helps you enforce community guidelines, detect policy violations, and maintain a safe environment for users worldwide.
Overview
The Detectify API allows you to moderate any user-submitted text with a single POST request. It returns a structured JSON response with per-category flags, confidence scores, human-readable reasons, and an overall risk summary—across multiple languages.
Features
- Multilingual Support: Analyze text in various languages for broader platform coverage.
- Multi-Category Detection: Spam, NSFW, Hate Speech, Harassment, Violence, Self-Harm, CSAM, Extremism, Misinformation, PII, and Obfuscation.
- Human-Readable Reasons: Each flagged category includes a concise rationale.
- Overall Risk Summary:
flaggedAny,highestScore,topCategory, andoverallScorefor quick assessment. - Zero Setup: Simple HTTP endpoint—no client libraries required.
API Endpoint
Content Moderation
- Method: POST
- Endpoint:
/detect - Description: Submit any text (up to 10,000 characters) in any supported language. Receive a JSON response detailing content violations and risk scoring.
Example Request & Response
Request
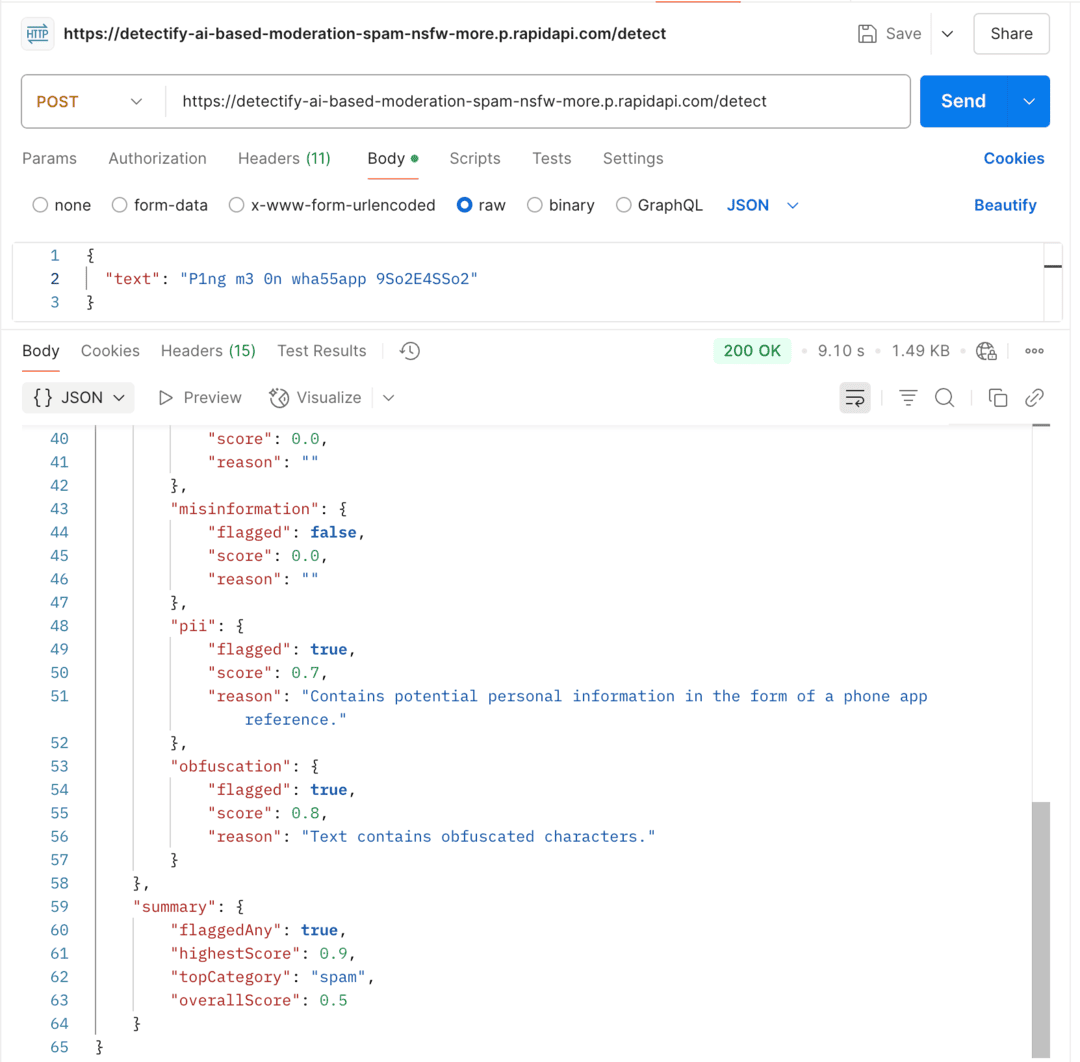
curl --request POST \
--url https://detectify-ai-based-moderation-spam-nsfw-more.p.rapidapi.com/detect \
--header "Content-Type: application/json" \
--header "X-RapidAPI-Key: YOUR_RAPIDAPI_KEY" \
--header "X-RapidAPI-Host: detectify-ai-based-moderation-spam-nsfw-more.p.rapidapi.com" \
--data '{
"text": "P1ng m3 0n wha55app 9So2E4SSo2"
}'
Response
{
"results": {
"spam": { "flagged": true, "score": 0.95, "reason": "Contains elements resembling spam or phishing attempts." },
"nsfw": { "flagged": false, "score": 0.0, "reason": "No NSFW content detected." },
"hateSpeech": { "flagged": false, "score": 0.0, "reason": "No hate speech detected." },
"harassment": { "flagged": false, "score": 0.0, "reason": "No harassment content detected." },
"violence": { "flagged": false, "score": 0.0, "reason": "No violence detected." },
"selfHarm": { "flagged": false, "score": 0.0, "reason": "No self-harm content detected." },
"csam": { "flagged": false, "score": 0.0, "reason": "No CSAM detected." },
"extremism": { "flagged": false, "score": 0.0, "reason": "No extremism detected." },
"misinformation": { "flagged": false, "score": 0.0, "reason": "No misinformation detected." },
"pii": { "flagged": true, "score": 0.85, "reason": "Contains potential personally identifiable information." },
"obfuscation": { "flagged": true, "score": 0.90, "reason": "Text includes obfuscated characters." }
},
"summary": {
"flaggedAny": true,
"highestScore": 0.95,
"topCategory": "spam",
"overallScore": 0.64
}
}
Usage
- Subscribe to Detectify on RapidAPI.
- Include your RapidAPI key and host in request headers.
- Send your text payload (in any supported language) to
/detect. - Parse the JSON response to automate moderation workflows.
Keep your platform safe, compliant, and user-friendly—automate multilingual content moderation with one simple endpoint.
See it in action!
Try Detectify now via RapidAPI: